The neural network has to lip-read the speech of the BBC announcers
Developers from Oxford University and the laboratory of Google DeepMind has created a system of artificial intelligence that can recognize speech lips in the real world, and she does this better than a human. For its study, the researchers used fragments of television BBC. The text of the article can be found on the website ArXiv.
Automatic speech recognition system based on gestures can be used in a variety of ways: for example, to hearing AIDS of new generation, biometric identification or investigation of crimes. Therefore, scientists have been working on the development of programs for “reading” on the lips, but their success in this area is very limited. Just this month, researchers presented the first system in the world LipNet, which can understand speech at the level of entire sentences better person. However, even it had flaws. The main drawback LipNet was that for checking the operation of the database was used with a limited number of speakers, who said the proposals built on the same principle. Such conditions recognized “greenhouse” even the developers themselves.
Read makinodan lip-reading computer
The authors of the new work presented a system Watch, Listen, Attend and Spell (WLAS), which recognizes the speech of the real presenters of BBC programs.
It is built on the same principle that LipNet: it is based on the combination of LSTM and the convolutional neural networks and machine learning methods. LSTM-neural networks are a type of recurrent neural networks, which are characterized by the presence of feedback.
Their main feature is that they are able to learn long-term dependencies and, consequently, to work with context in the long sentences (more about and LSTM recurrent neural networks you can read in our material). Convolutional neural networks, in turn, do well on the problem of image recognition and are suitable for frame-by-frame video analysis.
The system of WLAS trained by using a database consisting of 5 thousands of hours of recordings of TV programs BBC. In total it contained 118 thousand sentences that have been uttered by different people. First, artificial intelligence has learned to recognize a “lip” the words matching the lip movements of the speaker with subtitles, and then passed to the level of collocations and individual sentences. In addition, the WLAS were further trained to recognize the speech in the audio tracks.
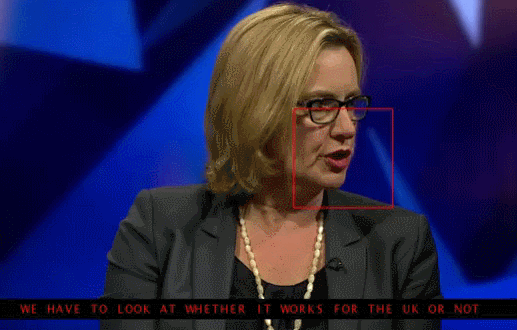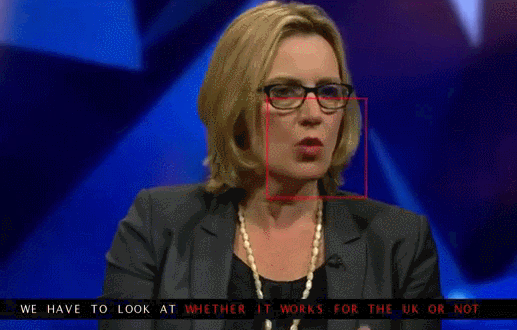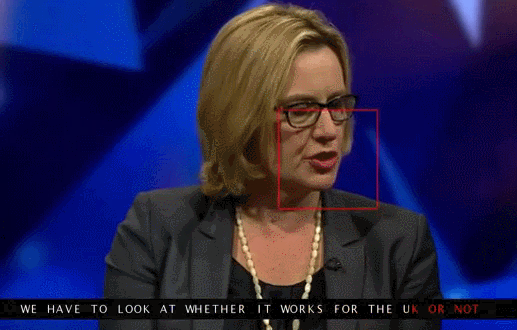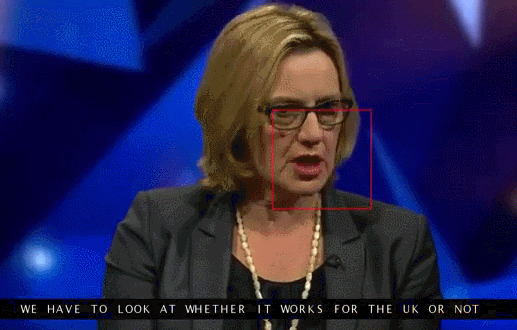
About 12 thousand sentences from the total database was used to test the new system. The tests showed that 46.8 percent of cases, WLAS correctly determines that said participant of the TV program. However, many errors were insignificant — for example, the program missed the “s” at the end of words. Thus the artificial intelligence managed to get around the person: the accuracy of specially trained people who deciphered 200 randomly selected video from the same database, reached only 12.4 percent (if the assessment excluded those proposals decryptor refused to work, then it increased to 26.2).
Read takenabout taught to mix several styles in one image
With this result WLAS bypasses all existing speech recognition system for facial expressions of man. However, it is not clear where it will be used by the program. The authors claim that it can help to improve the performance of such mobile assistants like Siri.
Recently Microsoft has announced that it managed to improve the system of recognition of oral speech, which is also based on the use of convolutional and LSTM-neural networks. Now the program that you plan to use voice assistant Cortana, the games console Xbox One and other programs, makes fewer mistakes than professional typing.
Christina Ulasovich